



Putting data sets together with your newly-hired data team does not mean automatic success in data intelligence. Here is why …
Has your organization hired a data scientist or two, run a few AI and machine learning projects, and then after nine months into the excitement, found all the efforts to have gone nowhere?
This can be a huge setback when organizational leaders probably invested a lot in the digitalization. It’s often been said that finding a good data scientist is like hunting for a unicorn! According to Tian Su, Director of Data Science/ML/Analytics, Walmart, such talent normally have a multitude of skills sets other than data analytics—they often bring with them a strong understanding of business intelligence, product visualization, UX and human psychology, pragmatism and curiosity.
However, finding data scientists and providing them with tons of data may not always lead to transferrable success. As talented as they have demonstrated themselves to be in previous work stints, these data scientists have to understand your organization’s customer base, product lines, and most important of all — be inducted into your corporation’s product mindset, said Su in a presentation she made on a recent virtual conference ATxSG.
Where is this all going?
After getting some really interesting insights from data sets, your data scientist has developed a machine solution and is now starting to look around to see which product to shoehorn the tech into.
However, product heads are scratching their heads with questions. Which product does this ML solution benefit most? How is it going to be implemented, into which tech stack? Who is going to maintain it? Who is going to gather data after implementation to fine-tune the learning algorithm? Where is all this going?
After a few such aborted efforts, some managements get disenchanted, thinking that AI is not adding value. Either there are no deliverables, or there are too many half-conceived ideas that cost too much to develop and have to be force-fed to product teams to find a way to make some use of them. Worst still, according to Su, some organizations never even reach this stage of confusion, because ideas are quickly formed and dropped well before any prototype got developed. The deep-seated causes of this waste of time and effort? The lack of a product mindset in guiding any ML project. This mindset consists of three key thrusts:
- User focus: Instead of finding a brilliant solution to a problem nobody ever brought up, AI projects must be laser focused on specific user issues and real problems needing a fix. Additionally, there must be focus on other user aspects such as ergonomics (user-friendliness), simple and intuitive user experience (UX); perceptiveness to boost discoverability, tolerance to mistakes, and ability to make predictive guesses that delight the user.
Any data science project that is not predicated tightly on user focus but on a mix of idealism and unspecific goals will likely create more questions than solutions.
In the case of Walmart’s user interface, Su cited how user-focused machine learning algorithms skip recommending what regular customers have been buying regularly. Instead, the system experiments with “recommender algorithms” tap a user’s past purchases to make predictions of what they may like (novelty), did not know they may like (diversity), or even convince them they have found something they find ideal (serendipity).
When user focus guides how any project gets approved and proceeds, the project’s success and future relevance will not be in doubt.
- Quick iteration and prototyping: Once the user focus is on target, the project can proceed to quick prototyping using mockups and wireframes. However, data scientists and ML engineers cannot create good prototypes unless they are inducted into the organization’s DNA. They should leave all pre-assumptions at the door and follow product managers to customer meetings to know their end users, to know how their own organization builds rapport with these customers, and to know real pain points and motivations on both sides of the business relationships.
Only with a sufficiently deep understanding of their target audience (customers), can data developers learn to LISTEN-THINK-DESIGN solutions that really benefit the organization and its customers. Also, with a good grasp of user focus from seeing customers, developers tend to ask for shorter development times (and are inspired to work along bite-sized milestones to Fail often, fail fast), as compared to developers who are just given staff briefings and told to come up with a schedule blindly.
The iteration part comes from developing a culture where developers are constantly fed user feedback to improve their prototypes in an agile manner. Without constant and iterative user feedback, even a solution that is developed quickly may end up flawed. - End-to-end thinking: Good data scientists can think holistically, from end to end, to turn ideas into practical solutions, especially when they have been given the right orientation of the corporate business strategy and culture. However, end-to-end thinking challenges them to think in terms of ML explainability; choice of using simple vs complex models to tune the app response times; scalability of their prototype to other parts of the organization; and the entire gamut of back-end considerations around machine learning (e.g., feature extraction, analysis tools, machine resource management, A/B testing, incentivization of user feedback etc.).
By incorporating good end-to-end thinking, your data science talent will be able to build robust, resilient, scalable and compoundable.
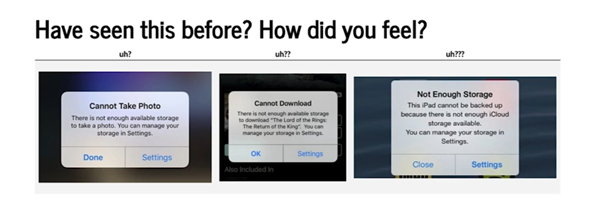
Su also mentioned how some organizations intentionally (or inadvertently) employed ‘Dark UX’ tactics that make the user experience complicated and confusing to subtly cause users to spend more money than they need to. This is not a good foundation for building good trust or reputation with data.













{kind=link}