



How can unconscious human bias be weeded out of the learning algorithms we create? Here is some food for conscious thought.
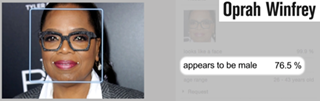
A recently released Netflix documentary ‘Coded Bias’ has generated a lot of discussion on algorithmic bias of late. The documentary has highlighted that most popular AI programs are trained with data sets that have a skew towards light-skinned males.
The initial approach in the use of these algorithms, was to enumerate the rules that humans used in decisioning, and then to transcribe these rules into code. This soon led to complex networks of algorithms that replicate a stripped-down version of the human mind, to learn from data the way humans do.
These neural networks are playing to the strength of the computers, in untiringly processing growing amounts of data to modify the classification rules that they initially began with. This construct has seemingly resulted in machines that learn at a low cost and are devoid of human frailties. Or has it?
No free lunch
Machine learning neural networks are focused on solving a specific problem and represent what is known as narrow or weak AI. This refers to the approach of using ML to solve specific problems, and it contrasts with strong AI which focuses on context and understanding along with the ability to solve general problems.
One of the advantages of weak AI is that it is very practical and has an application focus. This is therefore where a lot of corporate funding has gone into, over the past decades. In fact, the progress in the solution of narrow problems has reached a state where, in instances, these algorithms are able to compete convincingly with experts, despite the natural human advantage of understanding context and meaning.
However, the critics point out the fact that narrow AI is ultimately a blind classification tool, lacking context or understanding, and these critics worry that this black box approach to problem solving lacks a grasp of the underlying meaning and implication of its actions. They argue that the general problem-solving ability of the human mind can draw exceptions to the rule, derived from context and perhaps compassion, that is out of the reach of the current machine learning algorithms.
Besides lacking circumspection and awareness ML can inherit human biases. ML systems learn from past decisions or from other feedback loops that are set up based on current decision agents, typically humans. An ML algorithm typically optimizes a cost function based on a finite data set to reach the best version of an actual system that is currently in use.
In financial use cases, the best ML function could be one that decides who to extend credit to, but this algorithm could consequently decline an economically-disadvantaged group as the latter is deemed unable to repay a loan. In this case, that will be what the algorithm will iterate to: bias.
An algorithm works on assumptions or classifiers: without these it would produce no better than random results. These classifiers, statistically speaking, have the same error rate averaged over all possible distributions of the data. Hence, if they are better at modeling, say, credit performance, they would by virtue of this be worse at modeling other distributions. This is the gist of the aptly named ‘No free lunch theorem’. The decision outcomes from these algorithms can consequently be unfair and discriminatory.
Potential solution?
Unlike the philosophical issue of narrow AI, the statistical problem has a potential solution. There are various statistical approaches that have evolved to indicate the ‘fairness’ of ML algorithms.
In parallel with the evolution of the metrics of fairness, there has been a lot of progress in removing bias from ML through a variety of techniques.
- The first technique, pre-processing, focuses on the primary source of bias, which is data. The right effort in ensuring that we put together a balanced dataset is the starting point to fairness in ML.
- The second technique focuses on post-processing or altering the decision of the models to get to fair outcomes.
- A lot of academic research is currently centered around the third approach, which focuses on introducing fairness into the model training process.

The enormity of the underlying issue however is noteworthy, as the documentary tells us. Buolamwini’s research indicated, for instance, that current facial-analysis software show a mean error rate of 0.8% for light-skinned men and 34.7% for dark-skinned women. While the documentary ends predictably well, with regulatory changes halting a fast adoption of this yet ‘in development’ technology, we all know that real life is more complex and the issues around the subject, trickier.
The real solution will be in ensuring the right balance between: development and use of the tech, which could paradoxically bring greater economic equality by reducing process costs; and the impact of discrimination through of the unsupervised use of these algorithms.
In parallel, the convergence of narrow AI with strong AI will have to broaden the ability of the algorithms to work on that essential human quality of ‘exception making’. In the meantime, we will need regulatory oversight over the use of these models, given the gap in power between the users of these algorithms and those that are impacted—to ensure that we force the right balance in use vs abuse of the technology.
Perhaps, the last question this subject leaves us with, is of whether humanity will evolve enough to allow our algorithms to make a ‘human’ error.
Building consumer safeguards is key to the healthy deployment of algorithmic models in everyday life. Consumer digital demand and technology growth make the use of these models—especially when augmented by AI tools—essential to scale low cost access to financial products supporting inclusion. This will need to be balanced by the creation of appropriate frameworks to protect consumers against bias and ensure equity.
Widespread adoption of these fairness models, with appropriate regulatory support. will be key to the adoption of AI models at scale in financial services.













{kind=link}